Accelerating Nearest Neighbor Search in 3D Point Cloud Registration on GPUs
Qiong Chang, Weimin Wang, Jun Miyazaki
ACM Transactions on Architecture and Code Optimization, 2025
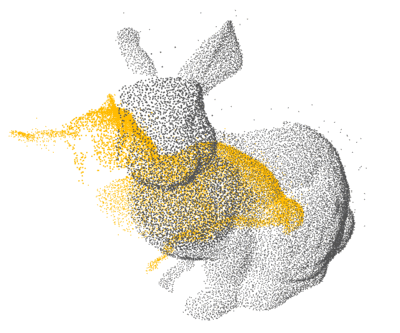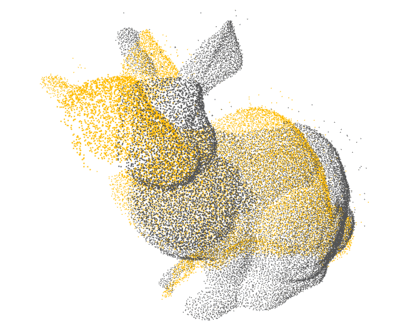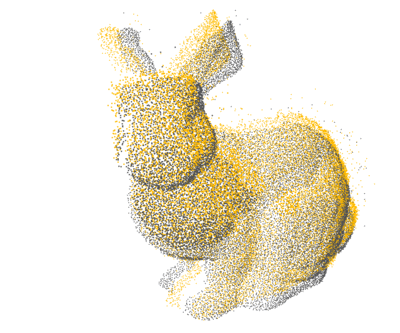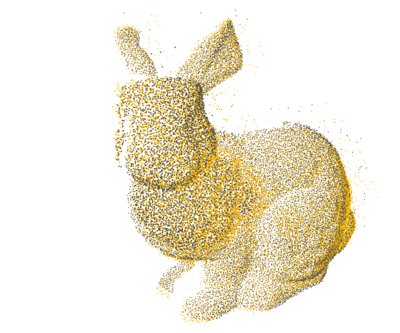
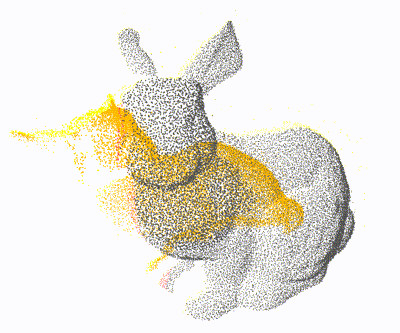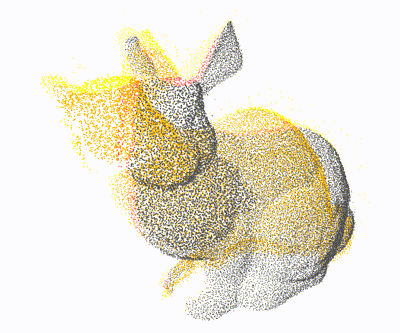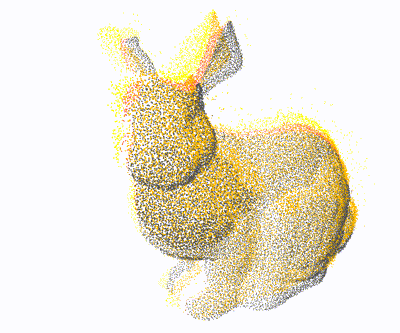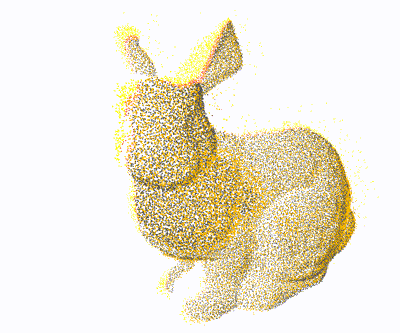
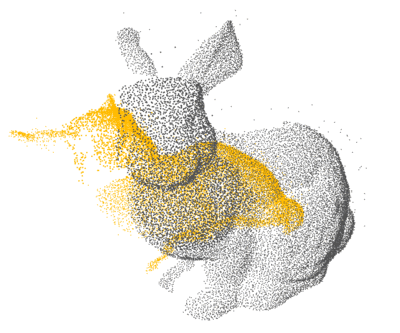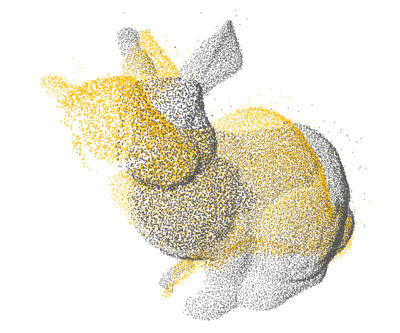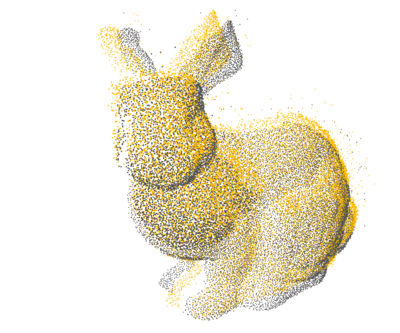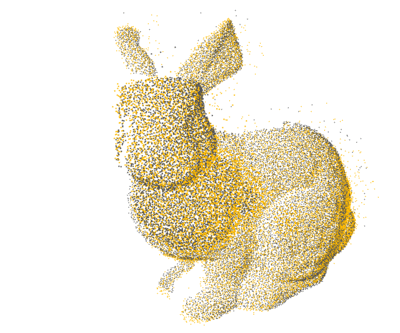
PCL: 1×
Open3D: 4×
Ours: 12×
 Proposed a GPU-accelerated method to significantly speed up nearest neighbor search for 3D point cloud registration, enhancing real-time performance in high-density spatial data processing.
Proposed a GPU-accelerated method to significantly speed up nearest neighbor search for 3D point cloud registration, enhancing real-time performance in high-density spatial data processing.
Faster than Fast: Accelerating Oriented FAST Feature Detection on Low-end Embedded GPUs
Qiong Chang, Xinyuan Chen, Weimin Wang, Xiang Li, Jun Miyazaki
ACM Transactions on Embedded Computing Systems, 2025
Input
CUDA-ORB: 1×
Ours: 2.2×
Proposed two methods to accelerate the most time-consuming steps in Oriented FAST feature detection: FAST feature point detection and Harris corner detection.
3D GNLM: Efficient 3D Non-Local Means Kernel with Nested Reuse Strategies for Embedded GPUs
Xiang Li, Qiong Chang*, Yun Li, Jun Miyazaki
ACM Transactions on Architecture and Code Optimization, 2025
Input
OpenCV-GPU: 1×
Ours: 5.5×
Proposed an efficient parallel implementation of the 3D Non-Local Means (NLM) denoising algorithm on GPU, significantly accelerating performance for high-resolution medical image processing tasks.
An Optimized GPU Implementation for GIST Descriptor
Xiang Li, Qiong Chang*, Aolong Zha, Shijie Chang, Yun Li, Jun Miyazaki
ACM Transactions on Architecture and Code Optimization, 2024
Introduced an optimized GPU-based implementation of the GIST descriptor, significantly accelerating image feature extraction for large-scale visual processing tasks.
TinyStereo: A Tiny Coarse-to-Fine Framework for Vision-based Depth Estimation on Embedded GPUs
Qiong Chang, Xin Xu, Aolong Zha, Yongqing Sun, Yun Li
IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024
Middle: z2zncc
28 fps on Jetson TX2
Bottom: sRRNet
22 fps on Jetson TX2
Implemented a lightweight coarse-to-fine stereo matching framework optimized for embedded GPUs, enabling efficient and accurate depth estimation under constrained computational resources.
Multi-Directional Sobel Operator Kernel on GPUs
Qiong Chang, Xiang Li, Yun Li, Jun Miyazaki
Journal of Parallel and Distributed Computing, 2023
Input
OpenCV-GPU: 1×
Ours: 11×
Proposed a GPU-accelerated multi-directional Sobel operator kernel for efficient and parallel edge detection across multiple gradient orientations.
Efficient Stereo Matching on Embedded GPUs with Zero-Means Cross Correlation
Qiong Chang, Aolong Zha, Weimin Wang, Xin Liu, Masaki Onishi, Lei Lei, Tsutomu Maruyama
Journal of Systems Architecture, 2022
Left (original ZNCC): 10 fps
Right (proposed Z2ZNCC): 20 fps
Implemented fast ZNCC feature matching on embedded GPUs, offering an effective real-time alternative to traditional Census in stereo matching.